
The KubeCon and CloudNativeCon took place from March 23rd to 26th in Amsterdam (hosted in the RAI Amsterdam). The event was massive, with more than 13,000 attendees (a bump of more than 10% compared to last year’s edition).
The first day (Monday) was dedicated to the co-located events and most of the knowledge paths were touching AI topics (I picked the Cloudnative AI + Kubeflow day, btw). The next three days were the main “official” keynotes and even though I tried my best to dodge the sketchy AI propaganda, most of the talks I attended mentioned a little bit of AI here and there.
Key insights from the event Link to heading
1. No one really knows what is the future of AI
I went to the event with grounded expectations, I knew that I would stumble upon a lot of AI companies trying hard to sell their products and some maintainers with a more down-to-earth view of software development; however, I was not prepared to hear a lot of sincere and humble “I don’t know”. During round tables and hands-on sessions the presenters brought some options and conjectures about the future of software development under AI, but no one was firm (nor confident) enough to ditch software development entirely.
2. A bunch of new companies emerged to surf the AI trend
As I mentioned, I was ready to get some stickers from companies wrapping GPUs and calling themselves disruptive AI firms and that happened too.
3. AI Inference is the new open source guiding star
A couple of years ago AI was based on experimentation. A huge amount of human and processing power was used for testing different and specific models. Therefore, training was a huge part of the MLOps pipeline.
With the boost of the Large [Language] Models (LLM, LVM, etc) the training from scratch became very expensive, so most of the companies are relying on RAG or a little bit of fine tuning. This movement shifted the resource usage from training to inference. 1
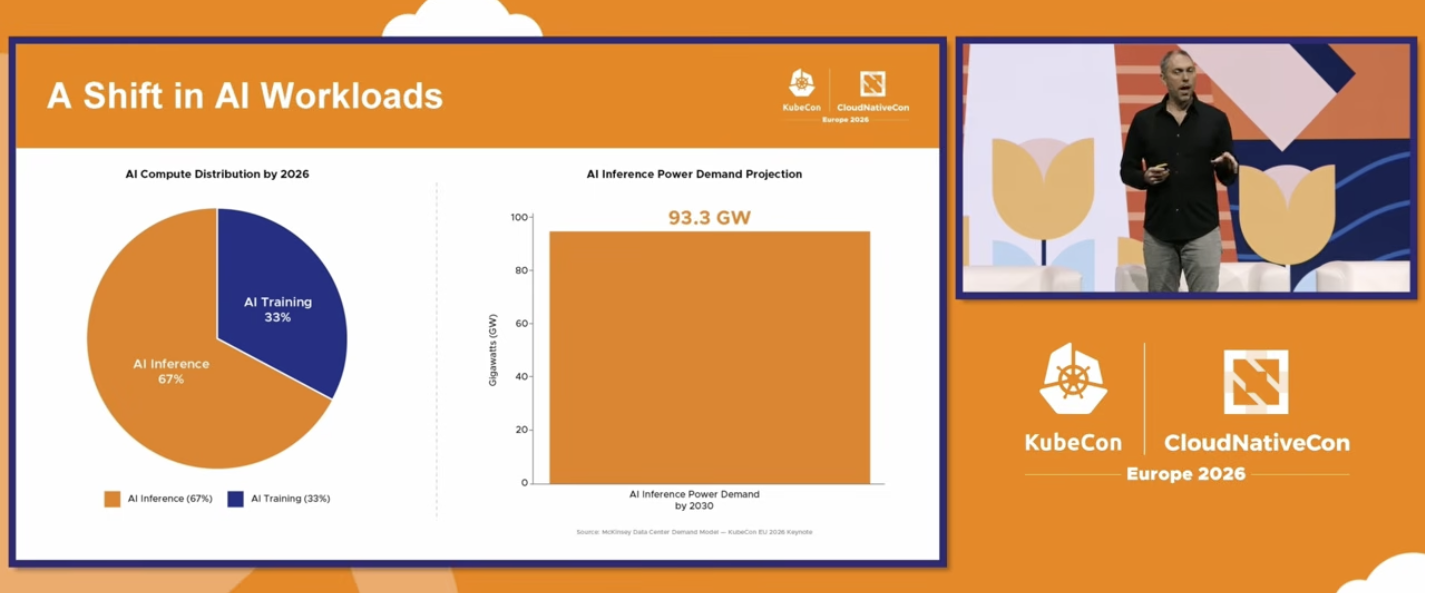
I believe this shift represents a huge transformation in the cloud infrastructure. In the past years it was common to have everything built in Python and executed on dedicated Datawarehouses / lakes. Databricks, Deltalake, Sagemaker and all the other cloud products were created based on the assumption that you could have everything (Data storing, ETL, feature storing, training and inference) in the same place. Model serving performance via dedicated technology was never a priority due to the fact that inference was only a small part of the ML Pipeline.
Those days are over. With the “all in” transition from training to inference, it’s mandatory to shift it to a more performant, cloud native, and cheaper technology. This includes the foundation (Distributed inference on Kubernetes) as well as the languages/stacks that are running on the other layers. The Kubernetes team has bet heavily on that.2
4. Kubernetes is ready to be the de-facto engine to model inference infrastructure
We cannot be that naive to assume they would fail to promote Kubernetes over any other tech stack in the KubeCon conference. The majority of the sessions were showing off Kubernetes capabilities as the foundation for model serving; However, Kubernetes has indeed acquired the title of the de-facto engine to serve microservices and we can expect that the same issues that it has overcome in the past years when people moved from monoliths to microservices are going to be quite similar to the ones faced by AI when moving from Lakehousing to distributed serving.3
For example, one big problem with AI serving right now is related to load balancing. The traditional stateless algorithms (round-robin, for example) do not take into account the memory and cache intensive characteristics of an AI prediction workload. These types of calculations are constantly iterating over context-window (with thousands or hundreds of thousands tokens) of the same user. So, it’s really important to balance the server load based on a mix of sticky-sessioning with available memory. The CNCF team is working on that too.4
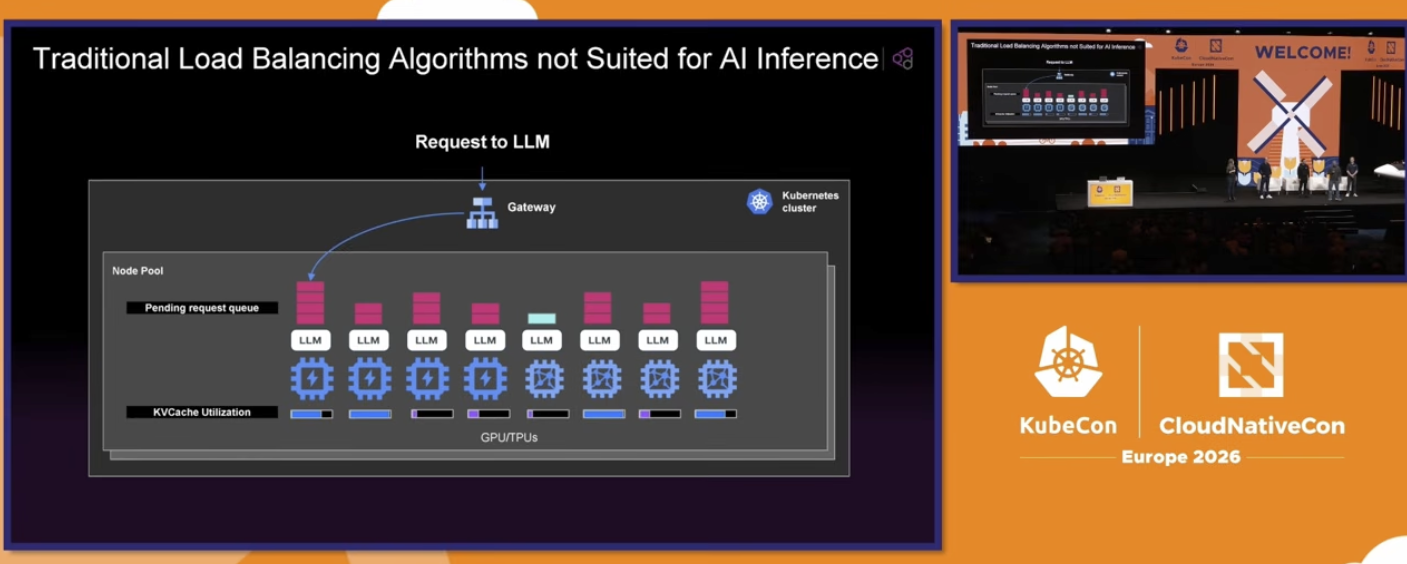
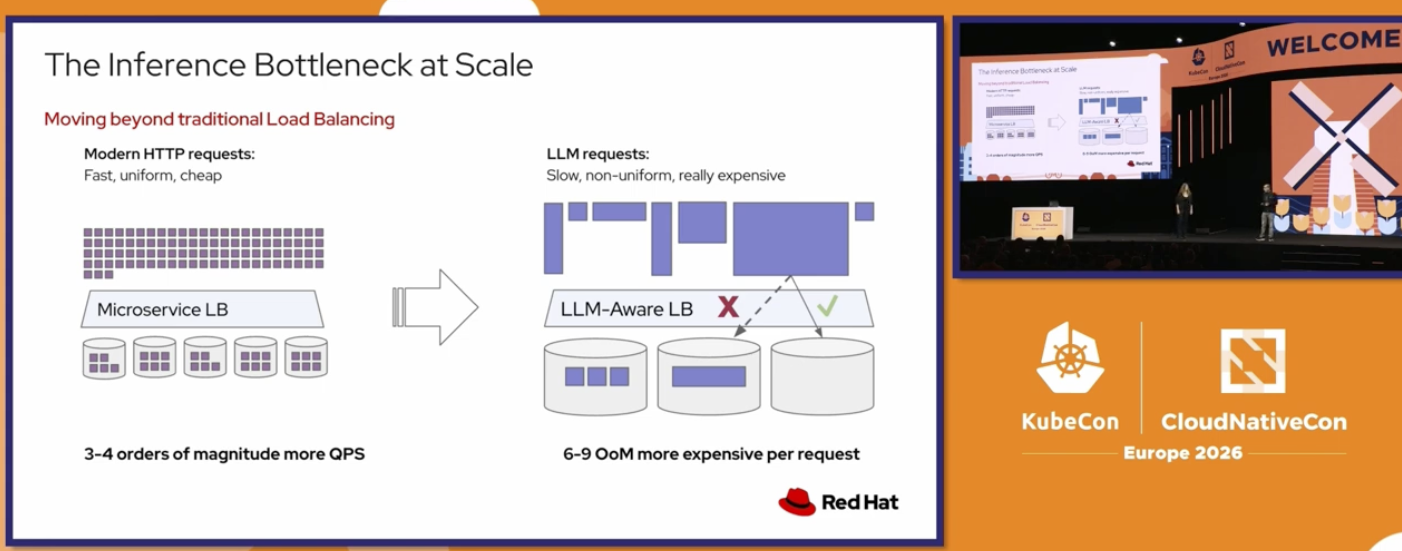
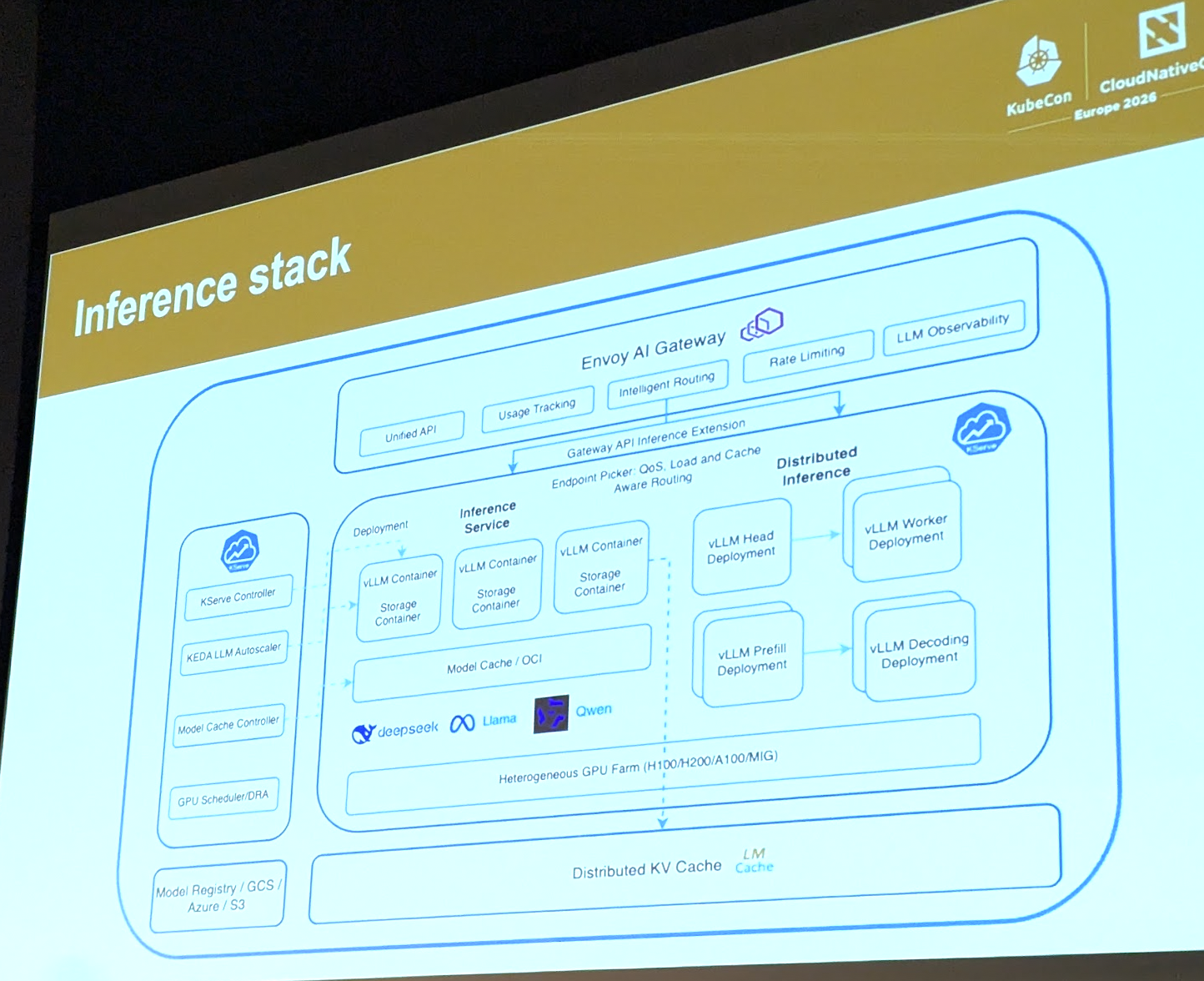
One big hit during the first keynote was the official addition of llm.d as an incubated project. LLM.d aims to solve the exactly this issue with distributed inference. It is Kubernates-native and deals with model loading, load balancing and model serving. It’s being used in combination with Kubeflow and vLLM as the default stack for Kubernetes AI prediction.
Here’s a reference architecture suggested by the maintainers of the KubeFlow 5
5. Transitioning back to specialized models
The Large Language Models were the ones responsible for booming the AI usage, they persuaded the decision makers that AI can be a first-class citizen in a service architecture. They have been effective and costly. Considering that most of the processing power is going to be used to serve inferences, it’s valuable and money-wise to find ways to improve the efficiency of these workloads throughout smaller and dedicated models.

It is a strong indicator that the next leap might be to find cheaper models with a “good enough” performance.
6. Platform Engineering is the ultimate guardrail against attacks, hallucination and data extraction
It seems that platform engineers are the less layoffable roles in the AI Era (competing with AI Engineer, maybe?). People are heavily relying on platforms to protect the customer against all the Agentic fragilities.6

The SDLC pre-AI era was based on a person building a piece of code containing a business rule that was defined and refined in a deterministic manner. That means the code writing contained a lot of guardrails on itself: 0) The UX (layout, UI and UX) was defined by a person based on expected human behaviors.
- The business rule was defined and written by a human who was supposed fact check and verify it.
- The business rule was then refined by a second person (senior developer or architect) that fact-check it again and drafted an algorithm.
- The business rule was written by a third person that was reading and fact checking that even more.
- The code is compiled and delivered.
With AI you can jump directly from step 0 (or even before that with a simple figma layout) to the step 4. AI gives the ability to get “working code” without all the fact checking from the steps that it automated out. The issue with this building life cycle is that AI was not trained to fact check but to produce working code even if this could impact sovereignt of data, security or scalability.
The standard solution to this is adding a senior engineer to review everything, which is the stage that we are right now. This is not full scalable though. The best alternative (and the one that people seem to be moving their investments) is building orthogonal platforms that can protect the customer using automation78

7. AI Producing Malware
It seems that AI is indeed democratic. It’s giving productivity boost to hackers as well. When I read the talk title “When Models Write Malware”, I thought that it would focus on AI creating new trojans or coders using AI to build new exploits, that was not the case. It seems some hackers are using AI to rewrite the same existing trojans but with different code signatures. Malware detection is based on pattern matching, most modern anti-virus have a library of malwares and their behaviors and are constantly comparing SHA, syscalls and file manipulation against an existing database of known unexpected actions. But what if you could tailor one specific malware per person that would execute the same “attack” but using different paths (e.g. different syscalls). Maybe that would not trigger any alarm.9
Interesting extra topics Link to heading
Most of the content is open
- CNCF Youtube Channel: https://www.youtube.com/@cncf/videos
- PDF/PPTX hosted on Sched: Event Talk Example
Cloud Native != Kubernetes Native
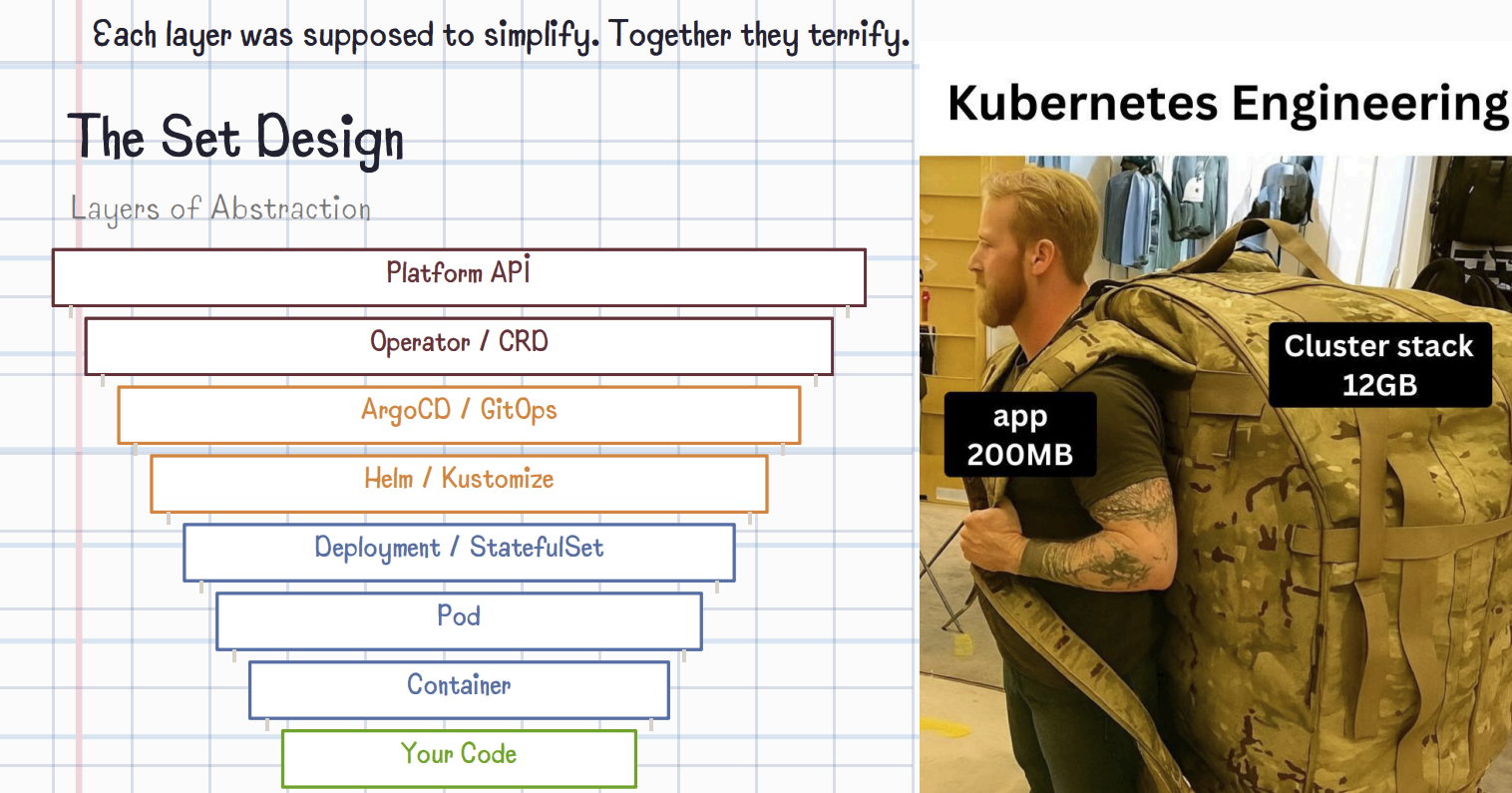
One interesting, funny and heterodox talk was from Prerit Munjal10. It was brave of him to go on and propose that Kubernetes native is not necessarily CloudNative and that maybe you don’t need kubernetes. That resonated with me more than I was expecting. I think it could be because the Kubernetes comes from the same Zoo as the microservices fetish. IDK.
Language was never a barrier
Maintainers, presenters and attendees were all confortably giving their speech no matter what their English speaking level was. Everyone was trying to learn from each other. I heard crystal-clear-spotless speakers and people who was still struggling a little bit. No one cared. (It’s always important to reinforce this to my Brazilian audience).
References Link to heading
-
Keynote: Welcome + Opening Remarks - Jonathan Bryce & Chris Aniszczyk. t = 704s talk ↩︎
-
Keynote: Welcome + Opening Remarks - Jonathan Bryce & Chris Aniszczyk. t = 900s talk ↩︎
-
Keynote: Welcome + Opening Remarks - Jonathan Bryce & Chris Aniszczyk. t = 1160s talk ↩︎
-
Keynote: Inference and Sovereign AI - Karena Angell & Vincent Caldeira. t = 74s talk ↩︎
-
From Cloud-Native Apps to Cloud-Native Platforms - Abby Bangser ↩︎